应用程序执行环境
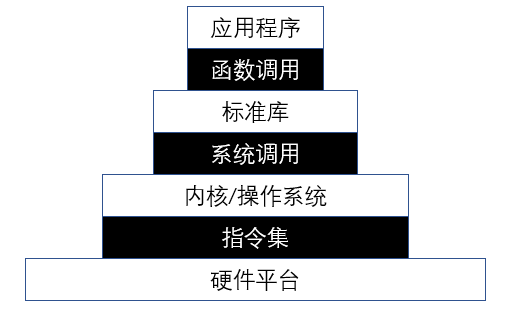
在现代操作系统上运行应用程序,需要多层次的执行环境栈支持,下图中上层使用下层提供的执行环境。
通常对于编译型语言编写的应用程序需要complier将source code编译为汇编码,assembler将汇编码转换为机器码,linker将多个机器码目标文件链接为一个机器码执行文件。一般而言,一个应用程序中会有多种函数调用,包括自定义函数以及标准库的函数,大部分的自定义函数仅仅是计算功能,不需要通过系统调用就可以进行,某些标准库函数如print、write、read以及创建子进程等就必须有操作系统的支持,应用程序调用标准库函数,标准库函数通过与操作系统之间的ABI(应用程序二进制接口)系统调用接口申请操作系统的支持,而操作系统仍然不能直接控制硬件进行机器码的执行,而是必须通过操作系统的执行环境获取和操作硬件信息。这个执行环境就是bootloader不仅仅引导启动操作系统而且常驻后台,为操作系统提供一系列的二进制接口,供操作系统获取和操作硬件信息,这些接口就是操作系统二进制接口,简称为SBI。对于risc-v处理器而言,SBI的实现是在M模式下运行的特定于平台的固件,它将管理S、U、H特权上的程序或通用的操作系统。
简而言之,应用程序的执行环境是complier而操作系统的执行环境是bootloader
从源代码到可执行文件
对于编译型语言编写的应用程序通常要经过以下四个步骤形成最终的可执行文件:
- 编译预处理:源代码(source code)经过预处理器(preprocessor)形成宏展开的源代码
- 编译:宏展开的源代码经过编译器(complier)编译为汇编程序
- 汇编:汇编程序经过汇编器(assembler)汇编成目标代码
- 链接:多个目标代码通过连接器(linker)链接成最终的可执行文件(executables)
上述过程以C语言为例,文件名为test.c
#include <stdio.h>
int main()
{
printf("Hello World!\n");
return 0;
}
编译预处理:
gcc -E test.c -o test.i# 1 "test.c" # 1 "<built-in>" # 1 "<command-line>" # 31 "<command-line>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 32 "<command-line>" 2 # 1 "test.c" # 1 "/usr/include/stdio.h" 1 3 4 # 27 "/usr/include/stdio.h" 3 4 # 1 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 1 3 4 # 33 "/usr/include/x86_64-linux-gnu/bits/libc-header-start.h" 3 4 # 1 "/usr/include/features.h" 1 3 4 # 424 "/usr/include/features.h" 3 4 # 1 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 1 3 4 # 427 "/usr/include/x86_64-linux-gnu/sys/cdefs.h" 3 4 # 1 "/usr/include/x86_64-linux-gnu/bits/wordsize.h" 1 3 4 ...... ...... ...... # 2 "test.c" 2 # 3 "test.c" int main() { printf("Hello World!\n"); return 0; }如上所述,预处理器仅仅只是将源代码中的宏展开以及将所用到的函数库
<stdio.h>文件复制一份展开到include处编译
gcc -S test.i -o test.s将宏展开的源代码编译为汇编码.file "test.c" .text .section .rodata .LC0: .string "Hello World!" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 leaq .LC0(%rip), %rdi call puts@PLT movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Ubuntu 8.4.0-1ubuntu1~18.04) 8.4.0" .section .note.GNU-stack,"",@progbits汇编
gcc -c test.s -o test.o,生成目标代码汇编器输出的每个目标文件都有一个独立的程序内存布局,描述了目标文件内各段的所在位置
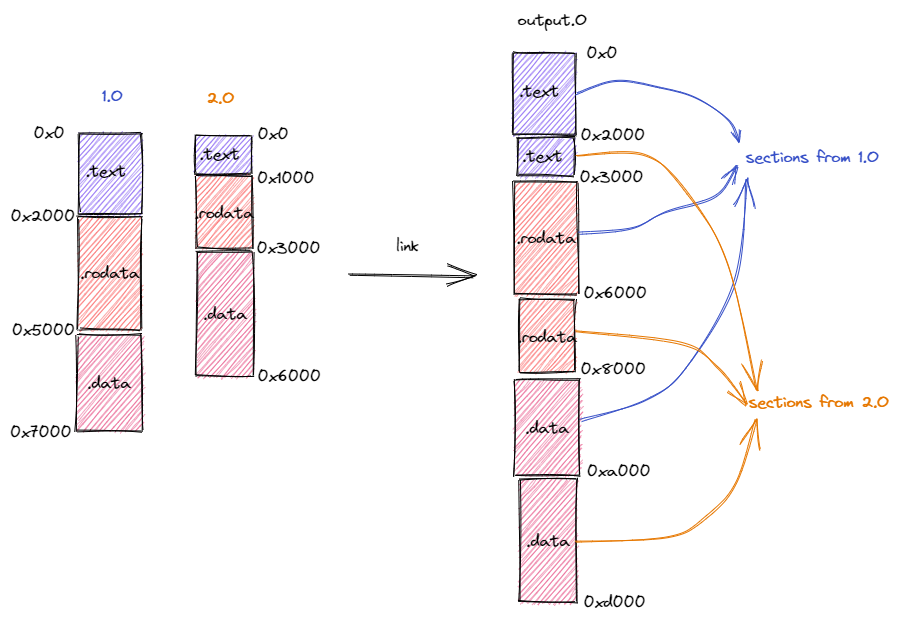
链接器将目标代码连接为可执行文件
gcc test.o -o test链接器将所有的目标文件整合成一个整体的内存布局生成一个可执行文件
将来自不同目标文件的段按照段功能在内存中重新排布,相同功能的段被排在一起后输出到可执行文件中。
将符号替换为具体地址。在模块化编程时候,一般一个程序包含多个模块文件,每个模块会提供一些向其他模块公开的内容如变量、函数等,变量名和函数名等被叫做符号,程序员通过调用变量名或者函数名就可以使用这些变量或者函数。但是在机器执行阶段,只能识别内存地址找到目标函数等,因此需要知道函数的绝对入口地址或者相对于当前PC的相对地址。链接器将完成从符号到具体地址的转换工作。
符号又可分为内部符号和外部符号,因为有些变量或者函数等仅对当前模块可见而对其他模块不可见。当一个模块文件经过编译预处理、编译、汇编生成目标文件之后,其内部符号就被转化为具体地址了,因为整个模块的内存布局已经确定下来。对于这个文件中的外部符号而言,其具体地址仍然无法确定,需要linker的进一步处理。这些外部符号放在目标文件一个名为符号表的区域用于后续的重定位。因为在连接过程中可能会涉及到内存布局的重新排布,因此内部符号也需要记录在符号表中用于后续的符号重定位生成具体地址。
系统调用
上述应用程序代码非常简短,但是却用到了不少的系统调用,使用strace工具查看如下strace ./test
execve("./test", ["./test"], 0x7ffc6e3dfef0 /* 27 vars */) = 0
brk(NULL) = 0x55ef2c92a000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=72487, ...}) = 0
mmap(NULL, 72487, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f017653b000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\240\35\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=2030928, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0176539000
mmap(NULL, 4131552, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f0175f33000
mprotect(0x7f017611a000, 2097152, PROT_NONE) = 0
mmap(0x7f017631a000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1e7000) = 0x7f017631a000
mmap(0x7f0176320000, 15072, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f0176320000
close(3) = 0
arch_prctl(ARCH_SET_FS, 0x7f017653a4c0) = 0
mprotect(0x7f017631a000, 16384, PROT_READ) = 0
mprotect(0x55ef2ab34000, 4096, PROT_READ) = 0
mprotect(0x7f017654d000, 4096, PROT_READ) = 0
munmap(0x7f017653b000, 72487) = 0
fstat(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 0), ...}) = 0
brk(NULL) = 0x55ef2c92a000
brk(0x55ef2c94b000) = 0x55ef2c94b000
write(1, "Hello World!\n", 13Hello World!
) = 13
exit_group(0) = ?
+++ exited with 0 +++
如此多的系统调用说明现代操作系统为了通用性而实现了大量的功能,对于非常简单的程序而言,有很多的功能是多余的。
应用程序执行平台
上述所有的应用程序及执行环境最终均离不开具体的硬件平台,不同的硬件平台会有不同的架构和指令集等。
对于一份用某种编程语言实现的应用程序源代码而言,编译器在将其通过编译、链接得到可执行文件的时候需要知道程序要在哪个 平台 (Platform) 上运行,是指 CPU 类型、操作系统类型和标准运行时库的组合。从上面给出的应用程序执行环境栈可以看出:
- 如果用户态基于的内核不同,会导致系统调用接口不同或者语义不一致;
- 如果底层硬件不同,对于硬件资源的访问方式会有差异。特别是如果指令集不同,则向软件提供的指令集和寄存器都不同。
它们都会导致最终生成的可执行文件有很大不同。某些编译器支持同一份源代码无需修改就可编译到多个不同的目标平台并在上面运行。这种情况下,源代码是 跨平台 的。而另一些编译器则已经预设好了一个固定的目标平台如JVM。
文档信息
- 本文作者:wendaocsmaster
- 本文链接:https://wendaocsmaster.github.io/2023/03/02/Operating-system-application-running-environment/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)